书库整理/数据整理
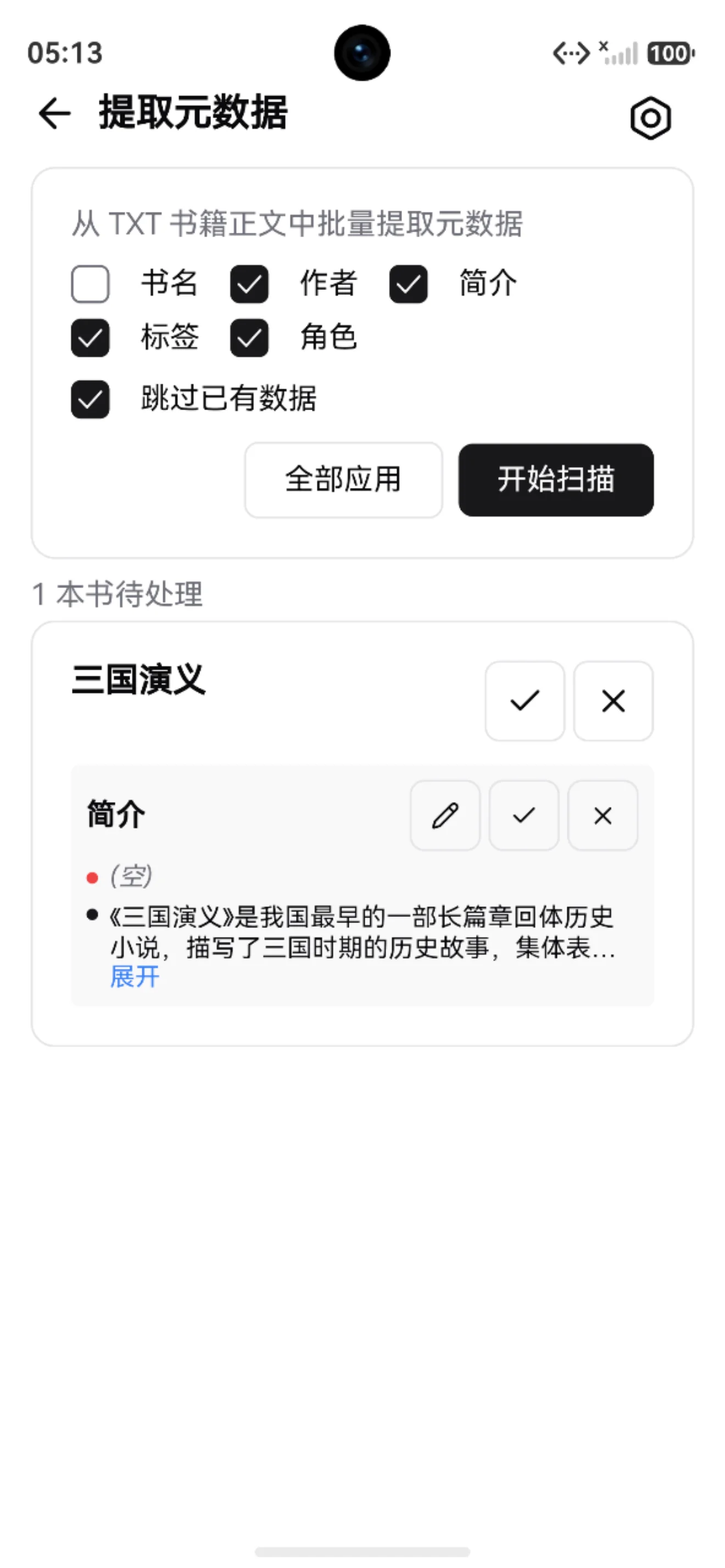
批量提取信息
从 TXT 书籍中批量提取书名、作者、简介、标签和角色,让书库信息更完整。
批量提取适合什么
批量提取适合 TXT 书籍信息不完整时使用。它会按规则从文件名和正文开头提取可用信息,再让你预览后决定是否应用。
常见场景:
- TXT 文件名混乱,需要提取书名作者
- 简介缺失
- 标签需要从正文或文件名中整理
- 正文开头写了主角、角色或人物列表,想整理成书籍角色
- 导入了很多 TXT,需要批量补充元数据
可以提取哪些信息
常见信息包括:
- 书名
- 作者
- 简介
- 标签
- 角色
具体可用项会受 TXT 内容结构、文件名格式和提取规则影响。
角色提取
角色提取适合正文开头有明确角色信息的 TXT,例如「主角:张三」「角色:张三、李四」这类格式。
提取后,角色会加入当前书籍的角色列表。后续可以用于书架列表显示角色、角色高亮、多角色朗读或角色相关整理。
注意:这里提取的是角色名,不是自动分析完整角色关系。如果你想让 AI 根据正文分析角色和关系,可以在 AI 助手里使用角色提取相关能力。
字数和页码在哪里处理
「批量提取信息」不负责提取页码,也不负责统计字数。
如果你只想补字数或页码,请使用工具里的「提取字数」。文字书籍会提取字数,PDF 或漫画类书籍会提取页码。
建议流程
- 先选择少量书测试
- 查看提取预览
- 确认规则是否适合这批书
- 再扩大到更多书
- 应用后检查书架和书籍详情
不同来源的书格式差异很大,不建议第一次就对整个书库应用新规则。
常见问题
书名或作者提取错了
通常是文件名或正文格式不统一。可以调整规则,或只对格式相近的一批书执行。
简介提取太长或太短
说明正文开头结构不稳定。可以先手动处理代表性书籍,再决定是否批量应用。
字数统计不准
字数统计不属于「批量提取信息」。请使用「提取字数」工具处理。
角色提取不出来
通常是角色信息没有写在正文开头,或格式和当前角色正则不匹配。可以调整角色正则,或先对格式相近的一批书测试。
操作前建议
批量应用前先导出备份。多设备使用时,批量整理完成后再同步。