书库整理/数据整理
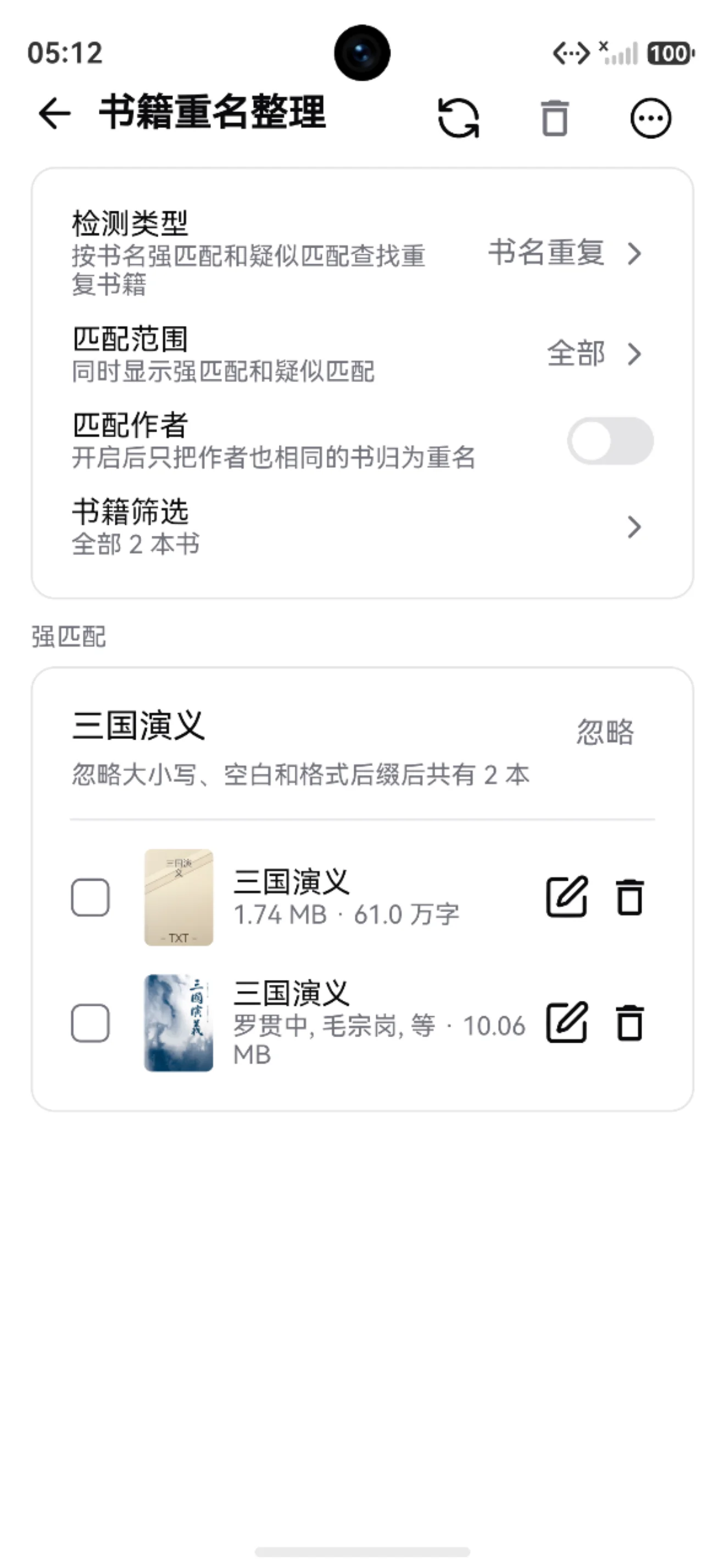
重名整理
找出可能重复的书籍,理解强匹配、疑似匹配和网盘文件名重复。
重名整理用来做什么
书库变大后,可能会出现同一本书导入多次、不同版本重复、文件名相似等情况。
重名整理用于找出这些可能重复的书,帮助你检查和清理。
常见匹配类型
强匹配
通常表示书名在忽略大小写、空白和格式后缀后非常接近。
这类结果更可能是真重复,但仍建议打开确认。
疑似匹配
会考虑版本号、括号、卷号等常见噪声。
这类结果可能是重复书,也可能是同系列不同卷。
网盘文件名重复
如果使用原始文件名存储,同名文件可能影响云端资源识别。
这类结果更适合在配置同步前或同步异常时检查。
怎么处理
建议:
- 先看强匹配
- 再看疑似匹配
- 打开书籍详情确认内容
- 决定保留哪一本
- 删除前确认笔记、进度和文件是否还需要
如果只是想暂时不看某组结果,可以使用忽略。被忽略的重复关系后续不会再出现在结果里,除非你清空忽略项。
删除前注意
删除书籍可能影响笔记、进度、标签关联和同步结果。
如果你不确定哪一本更完整,先不要删除。可以先导出备份,或只处理确认重复的书。